






The different tools and technologies that we often use when developing software add complexity to our systems. One of the challenges that we face in web development is that we are often writing the backend and the frontend in different languages and type systems. To build reliable applications we need a way to connect both.
We need to make sure our applications are reliable and do not break when the API changes. We can build a bridge that helps us to traverse safely between the backend and the frontend. We can do that with a code generation tool that allows us to use the same types on both sides of the application.
You will see a real-life case, using Haskell as a backend language, how you can get Reason (OCaml) types and JSON serialization/deserialization almost for free using Generics and how you can make sure your serialization is correct with automatic golden test generation.
The topic of this blog post was presented at Compose Conference New York in July 2019. Check out this and the rest of the amazing talks here!
Why did we choose Reason?
Reason is a new syntax and toolchain for OCaml created by Facebook. OCaml is a decades old language that has been relegated mostly to academia but has inspired a lot of new languages (Rust, F#). Sadly, it does not have the kind of community we need for web development where things move at high speed.
Facebook built Reason to solve real-life problems in production apps - Facebook Messenger is over 50% migrated to Reason, and they reduced bugs and compilation times by doing so.
When we talk about toolchain, we're talking about BuckleScript. BuckleScript is part of the Reason ecosystem. It is a compiler that takes Reason code and produces JavaScript code. The code BuckleScript produces is ready to use, or, if you want, you can use your favorite bundler to deploy your app. One of the best BuckleScript features is that it produces really performant and readable code. When you open a "compiled" file you can understand most of it.
So... why did we choose Reason? Well, for several reasons (no pun intended):
- Reason is an awesome way (if not the best way) to write React Apps: React was originally developed in StandardML (a cousin of OCaml), and React features like immutability and prop types feel a little foreign in JavaScript, but they are right at home in Reason.
- It has a great type system, which makes developing and refactoring a breeze. OCaml implements the Hindley–Milner type system, which allows parametric polymorphism. The type inference engine is so sophisticated that there is almost no need to supply type annotations, thus making our code extra clean.
- It's functional: Functional programming makes our code cleaner, more composable and easy to maintain. This, in combination with the type system, gives us compilation error messages that helps us to know not only where the error is but also what type of value we need.
- JS interop: Unlike Elm - a pure and functional language based in Haskell - JS interop is very easy in Reason. The downside is that your code can have uncontrolled side effects and - possibly - runtime errors.
- Reason leverages both the OCaml community and JS community and that gives us a unique ecosystem to work with.
There are other alternatives to work with types like TypeScript or Flow. While they are much better than using plain JS, they don’t provide the same guarantees. TypeScript and Flow add types to JavaScript too, but they do so by extending the language with all the problems and pitfalls JS already has. Reason, on the other hand, starts from the rock-solid foundation that is OCaml and then builds up its ease of use and community development that JS provide.
How did we implement it?
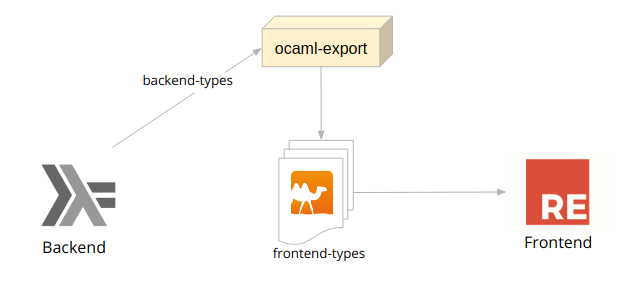
The types of our backend application were defined in Haskell and we wanted to use the same types in our frontend application. Since Haskell and OCaml types are similar in a semantic way, we decided to use a tool to transform them. ocaml-export is a tool that takes Haskell types and - using Generics - can analyze the type and make it an OCaml type so we can use it in our Reason frontend.
In Haskell (or in functional programming in general) we can define two kinds of types: Product Types and Sum Types.
Product types are what most people are familiar with. They correspond with records or classes in other languages. They describe a type that is composed of two or more other types.
Sum types are not very common in procedural languages. They are somewhat like union types in C. They describe a type that belongs to a set of possible values.
Here is an example of a product type in Haskell. It describes a User that contains both a String and an Int:
data User = User
{ name :: String
, age :: Int
}
A sum type in Haskell looks like this:
data Status
= Inactive String
| Active
The type Status is either Active or Inactive. Notice that the Inactive constructor has a String attached to it.
OCaml has the same kinds of basic types as Haskell. In fact, you can do a one-to-one mapping of the types without losing information. Here is how ocaml-export automatically generates the above examples:
type user =
{ name : string
; age : int
}
type status =
| Inactive of string
| Active
JSON encoding
This tool also generates JSON serialization and deserialization functions in OCaml. It does this by assuming we're using the bs-aeson library. Our previous examples would look like this:
let encodeUser x =
Aeson.Ecode.Object_
[ ("name", Aeson.Encode.string x.name)
; ("age", Aeson.Encode.int x.age)
]
This function will take a user object and serialize it into a JSON string of the form:
{
"name": "Kurt Cobain",
"age": 27
}
With the sum type the encoding function is a little trickier but works in the same fashion. We make the JSON with the type constructor description in the tag field and the contents (if any) in the contents field. These are the Aeson Haskell library defaults. The encodeStatus function will be generated as follows:
let encodeStatus x =
match x with
| Inactive y0 ->
Aeson.Encode.object_
[ ("tag", Aeson.Encode.string "Inactive")
; ("contents", Aeson.Encode.string y0)
]
| Active ->
Aeson.Encode.object_
[ ("tag", Aeson.Encode.string "Active")
]
This will produce a JSON object of the form:
{
"tag": "Inactive",
"contents": "description"
}
Or:
{
"tag": "Active"
}
Notice how all these functions are type safe. The variable y0 cannot be anything other than a string, yet - thanks to OCaml's powerful type inference engine - our code does not look polluted with type annotations. The engine knows that x is of type status because it has to match with its constructors and it knows y0 is a string because it has to match with the Inactive constructor. Also, OCaml forces us to deal with all the possible matches of the status; if we somehow forget to deal with the Active constructor, our code won't compile.
JSON decoding
The same way we get JSON encoding for free with ocaml-export, we also get decoding. That is when we get a JSON response from the backend, we have a function that allows us to transform that JSON object into OCaml in a type-safe way.
This is what the decodeUser function looks like:
let decodeUser json =
match Aeson.Decode.
{ name = field "name" string json
; age = field "age" int json
}
with
| v -> Belt.Result.Ok v
| exception Aeson.Decode.DecodeError message -> Belt.Result.Error ("decodeUser: " ^ message)
Notice how this function doesn't fail. It will always return a Result. In this case it will return either an Ok wrapping the decoded value or an Error wrapping
the error message. This is similar to how Either works in Haskell, and it forces us to handle the error state in a type-safe way.
The sum type decoding works in a similar fashion:
let decodeStatus json =
match AesonDecode.(field "tag" string json) with
| "Inactive" -> (
match Aeson.Decode.(field "contents" string json) with
| v -> Belt.Result.Ok (Inactive v)
| exception Aeson.Decode.DecodeError message -> Belt.Result.Error ("Inactive: " ^ message)
)
| "Active" -> Belt.Result.Ok Active
| tag -> Belt.Result.Error ("Unknown tag value found '" ^ tag ^ "'")
| exception Aeson.Decode.DecodeError message -> Belt.Result.Error message
Again, all the OCaml code that is presented here is autogenerated by ocaml-export and it is production-ready code that can be used in your Reason app. :tada:
Testing
Although the type system helps us to make sure our program is correct, it can't replace tests. We need to make sure that the serialization/deserialization that happens in our frontend is the same as the one in our backend. And tests are the only way to achieve that.
Luckily, ocaml-export also generates JSON golden files for all the types we feed into it. These golden files are generated using Aeson and Arbitrary from the Haskell backend. These JSON objects are examples of how our backend serializes requests.
Now we have to make tests to prove that our OCaml code can read those files and then serialize the resulting object into the exact same JSON structure we started with. Of course, ocaml-export will generate the test suite too. Here is how it looks:
let () =
AesonSpec.goldenDirSpec
OnpingTypes.decodeUser
OnpingTypes.encodeUser
"user test suite"
"golden/User";
We use bs-aeson-spec to automate our tests. The goldenDirSpec function takes a serialization and a deserialization function and runs them against the golden files, assuring that the serialization in our frontend works in the same way as in our backend.
What does it look like?
You can take a look at an example here. You’ll find a complete Haskell backend and Reason frontend, along with the bridge between them. When you compile the frontend, all the types from the backend will cross that bridge into the frontend and they will be tested and used by the frontend. Take a look and tell us what you think!
What's next?
There are a couple of issues still in development. The project is open source and welcomes contributions.
- Support for recursive types
At the moment, you cannot generate types that reference themselves (think linked lists or tree-like structures). It is possible to build such types in OCaml, but we need a way to detect a cyclic structure in Generic Haskell to translate that to the migrated type.
- Resolve type dependency order
The way OCaml works, a type has to be declared before you can use it. That is not the case for Haskell where the declaration order of dependencies does not matter. We would have to create a dependency graph of our types and then migrate those types so that there aren’t any dependency problems (and also to avoid cyclic dependency).
- Automatically create
bs-fetchcalls using servant route types
Besides generating the types, the golden files and the tests, it would be a nice feature to generate fetch functions (using bs-fetch) for the servant route types. That way you could create a complete frontend infrastructure automatically.
Final words
Static typing is a very important aspect of software development. It helps you catch type mismatches sooner - at compile-time rather than run-time - and it can help reduce the likelihood of some kinds of errors. This technique does not only apply to this use case. You can use it when your boundaries have a different type system and you want to take advantage of an interface defined with strong types.
By bridging Haskell and OCaml this way, we are bringing type safety to the interaction between the backend and the frontend, and we are now reducing errors and mismatches at the integration level. This allows us to refactor with greater confidence since a large class of errors introduced during refactoring will end up as type errors.